Vercel provider for StackQL available
· 3 min read
info
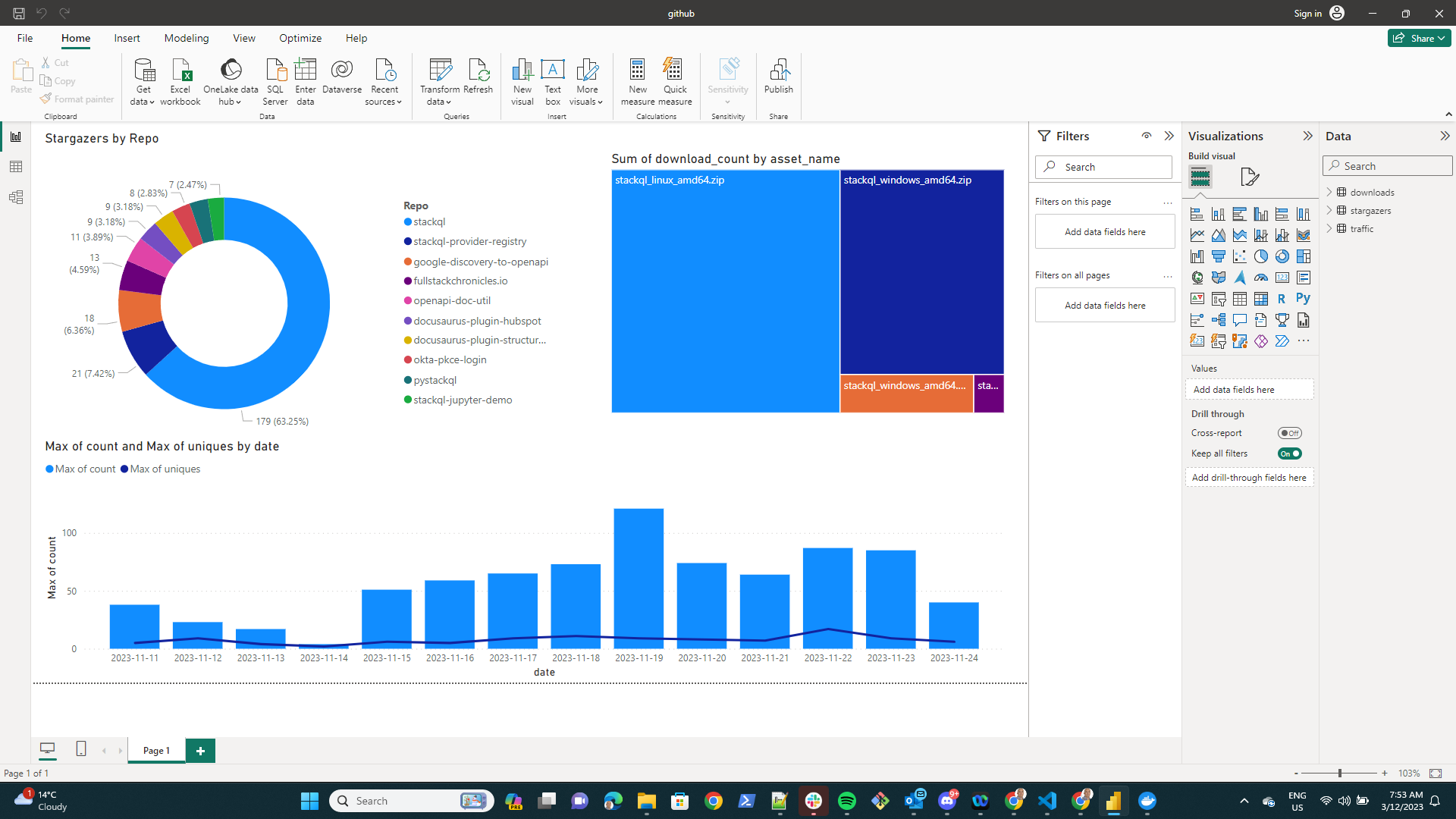
stackql is a dev tool that allows you to query and manage cloud and SaaS resources using SQL, which developers and analysts can use for CSPM, assurance, user access management reporting, IaC, XOps and more.
The StackQL provider for Vercel is now available! Developers can directly query, analyze, and report on builds, deployments, projects, domains, log_drains, and more. The StackQL Vercel provider can also be used to retrieve logs, manage certificates, replicate your deployment environment locally, manage Domain Name System (DNS) records, and more ... using SQL.
More information about the Vercel provider for StackQL is available here. Here are some sample queries to get you started:
- Projects
- Deployments
- Aliases
- Teams
- Users
SELECT id,
name,
accountId,
framework,
JSON_EXTRACT(targets, '$.production.meta.githubCommitOrg') as github_org,
JSON_EXTRACT(targets, '$.production.meta.githubCommitRepo') as github_repo,
JSON_EXTRACT(targets, '$.production.meta.githubCommitRef') as github_branch
FROM
vercel.projects.projects
WHERE teamId = 'gammadata';
/* example results:
|----------------------------------|--------------|-------------------------------|-----------|--------------|--------------|---------------|
| id | name | accountId | framework | github_org | github_repo | github_branch |
|----------------------------------|--------------|-------------------------------|-----------|--------------|--------------|---------------|
| prj_HfRAMu9goUsA93XNrgtllDGEaabc | gammadata-io | team_YWb92ThiM8OkiGNDlDAlPDEF | nextjs | gammastudios | gammadata.io | main |
|----------------------------------|--------------|-------------------------------|-----------|--------------|--------------|---------------|
*/
SELECT name,
datetime(createdAt / 1000, 'unixepoch') as created_at,
inspectorUrl as inspector_url,
ready,
SUBSTR(JSON_EXTRACT(meta, '$.githubCommitSha'), 1, 7) as github_sha
FROM vercel.deployments.deployments
WHERE teamId = 'gammadata';
/* example results:
|--------------|---------------------|------------------------------------------------------------------------|---------------|------------|
| name | created_at | inspector_url | ready | github_sha |
|--------------|---------------------|------------------------------------------------------------------------|---------------|------------|
| gammadata-io | 2023-10-06 22:21:44 | https://vercel.com/gammadata/gammadata-io/AwVH1FfZLCB592hD1qqb4xbTZctC | 1696630955301 | 7b0b82a |
|--------------|---------------------|------------------------------------------------------------------------|---------------|------------|
| ... | ... | ... | ... | ... |
|--------------|---------------------|------------------------------------------------------------------------|---------------|------------|
| gammadata-io | 2023-10-06 22:18:04 | https://vercel.com/gammadata/gammadata-io/2Tt4bTtQZNC5NBuuzkEYU6TwWvjX | 1696630731929 | e0e48cb |
|--------------|---------------------|------------------------------------------------------------------------|---------------|------------|
| gammadata-io | 2023-09-01 04:42:31 | https://vercel.com/gammadata/gammadata-io/7YmWz95FJH8FqNFesJURNimHrRTV | 1693543374425 | 28976a5 |
|--------------|---------------------|------------------------------------------------------------------------|---------------|------------|
*/
SELECT
alias, redirect
FROM vercel.aliases.aliases
WHERE teamId = 'gammadata'
AND projectId = 'prj_HfRAMu9goUsA93XNrgtllDGEaabc';
/* example results:
|---------------------------------------------------------------|----------------------|
| alias | redirect |
|---------------------------------------------------------------|----------------------|
| gammadata-io-git-feature-content-updates-gammadata.vercel.app | null |
|---------------------------------------------------------------|----------------------|
| ... | ... |
|---------------------------------------------------------------|----------------------|
| gammadata.io | www.gammadata.io |
|---------------------------------------------------------------|----------------------|
| gammadata-io-gammadata.vercel.app | null |
|---------------------------------------------------------------|----------------------|
*/
select
id,
name,
slug,
created
from vercel.teams.teams;
/* example results:
|-------------------------------|------------|-----------|--------------------------|
| id | name | slug | created |
|-------------------------------|------------|-----------|--------------------------|
| team_YWb92ThiM8OkiGNDlDAlPDEF | Gamma Data | gammadata | 2023-08-04T22:30:02.554Z |
|-------------------------------|------------|-----------|--------------------------|
*/
select id,
username,
JSON_EXTRACT(billing, '$.plan') as plan,
importFlowGitProvider as git_provider
from vercel.user.user;
/* example results:
|--------------------------|--------------------------------|-------|--------------|
| id | username | plan | git_provider |
|--------------------------|--------------------------------|-------|--------------|
| 7vvpEoXx1Q9SkJzY0DyUdXYz | jeffreyaven-gammadataio | hobby | github |
|--------------------------|--------------------------------|-------|--------------|
*/
Give us a ⭐ on GitHub