Sumologic Provider for StackQL Now Available
The StackQL Sumologic provider is now available in the public StackQL Provider Registry. Docs are available at sumologic provider docs.
StackQL is an intelligent API client which uses SQL as a front-end language. StackQL can be used for querying cloud and SaaS providers, as well as provisioning and lifecycle operations.
The StackQL Sumo provider can query, create, update and delete Sumologic collectors and sources, view and manage ingest budgets, health events, dashboards, user and account access and activity, and more.
Some example queries include:
SELECT id, name FROM sumologic.collectors.collectors WHERE region = 'au';
or using built-in functions to simplify and format query outputs, such as:
SELECT alive, datetime(lastSeenAlive/1000, 'unixepoch') AS lastSeenAliveUtc,
datetime(lastSeenAlive/1000, 'unixepoch', 'localtime') AS lastSeenAliveLocal
FROM sumologic.collectors.collectors
WHERE region = 'au' AND id = 116208196;
another example...
SELECT id, email,
firstName || ' ' || lastName AS fullName,
isMfaEnabled,
lastLoginTimestamp,
round(julianday('now') - julianday(lastLoginTimestamp), 0) as daysSinceLastLogin
FROM sumologic.users.users WHERE region = 'au';
An example using StackQL with the Sumologic provider to query users and roles and join the results to get a list of users and their roles:
SELECT u.email as email, r.name AS role
FROM sumologic.users.users u
JOIN sumologic.roles.roles r
ON JSON_EXTRACT(u.roleIds, '$[0]') = r.id
WHERE u.region = 'au' AND r.region = 'au';
An example using StackQL and Jupyter is shown here (see stackql/stackql-jupyter-demo):
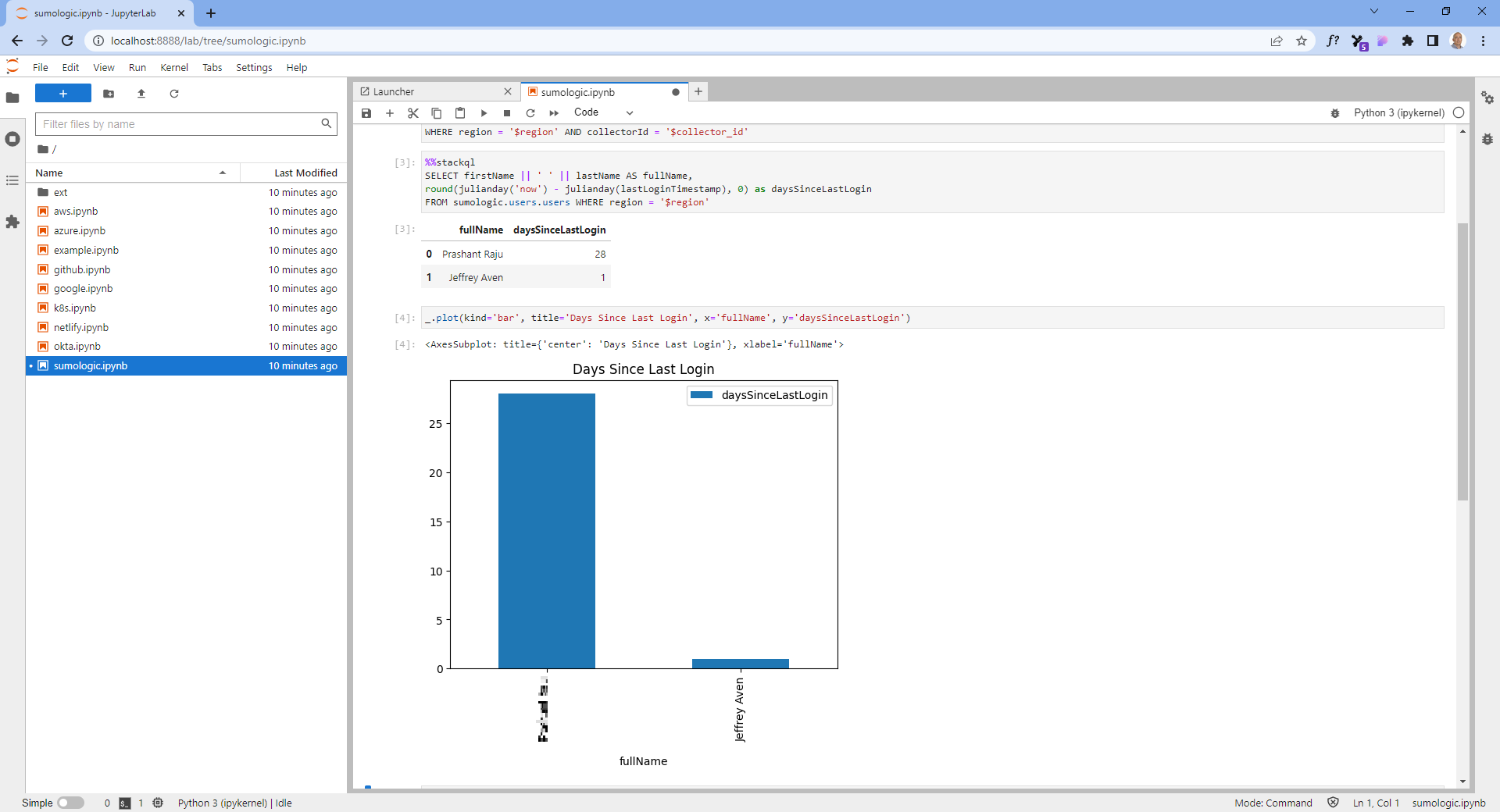
StackQL can also be used to provision objects in Sumologic, the following query can be used to create a collector for instance:
INSERT INTO sumologic.collectors.collectors(region, data__collector)
SELECT 'au',
'{ "collectorType":"Hosted", "name":"My Hosted Collector", "description":"An example Hosted Collector", "category":"HTTP Collection" }';
Let us know what you think!