Have you received one of these?
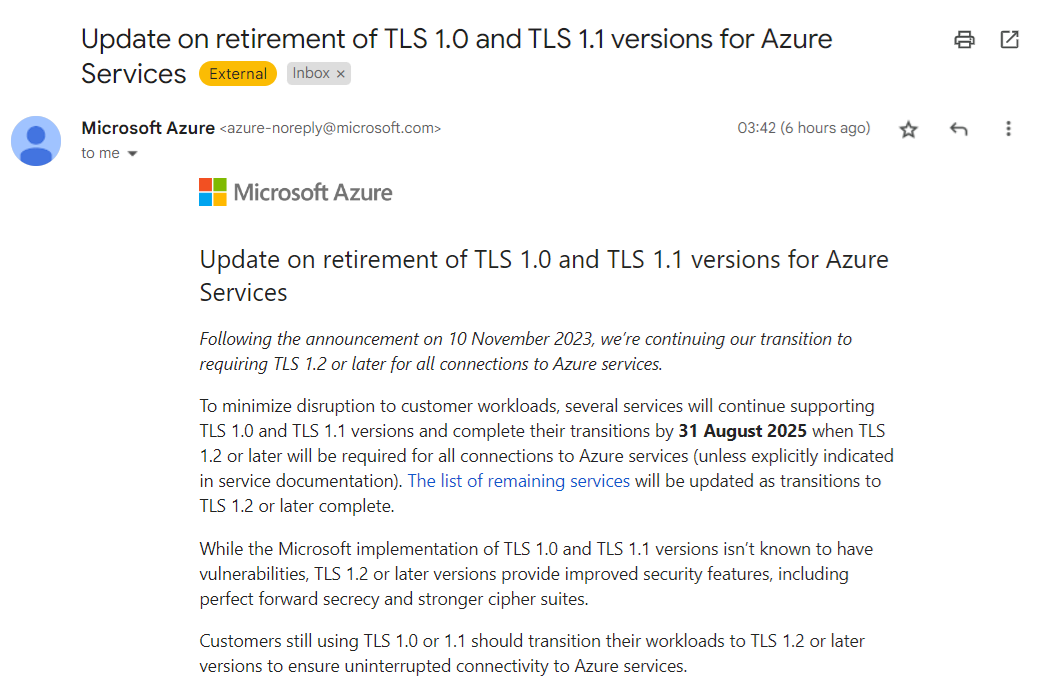
Microsoft Azure is retiring TLS 1.0 and 1.1 for its services, requiring customers to transition to TLS 1.2 or later to ensure uninterrupted connectivity. If you have workloads still using older TLS versions, you’ll need to update them.
Using StackQL to Identify Non-Compliant Resources
With StackQL, you can quickly identify resources in your Azure environment that are still using older TLS versions. This article shows how to leverage StackQL queries to check various Azure services for compliance.
Prerequisites
- Pull the latest StackQL provider for Azure using
REGISTRY PULL azure. - Authenticate with Azure using StackQL by setting up your credentials as environment variables (or using your existing
az loginsystem/session authentication).
Queries to Run
Below are example queries you can use to identify resources affected by the TLS 1.2 requirement (use your subscriptionId of course):
1. Check Application Gateway Configurations
Azure Application Gateways may support older TLS versions. Run the following query to get their configurations:
SELECT
id,
name,
JSON_EXTRACT(properties, '$.sslPolicy') as ssl_policy,
JSON_EXTRACT(properties, '$.defaultPredefinedSslPolicy') as default_predefined_ssl_policy
FROM
azure.network.application_gateways
WHERE
subscriptionId = '123e4567-e89b-12d3-a456-426614174000'
AND ssl_policy IS NOT NULL
AND JSON_EXTRACT(properties, '$.sslPolicy') NOT LIKE '%TLS12%';
This query lists all Application Gateways configured with TLS versions lower than 1.2.
2. Inspect App Service Configurations
If you use Azure App Services (Web Apps), check their TLS configurations with this query:
SELECT
id,
name,
JSON_EXTRACT(properties, '$.httpsOnly') as https_only,
JSON_EXTRACT(properties, '$.siteConfig.minTlsVersion') as min_tls_version
FROM
azure.app_service.web_apps
WHERE
subscriptionId = '123e4567-e89b-12d3-a456-426614174000'
AND JSON_EXTRACT(properties, '$.siteConfig.minTlsVersion') < '1.2';
This returns all web apps that allow connections using TLS versions older than 1.2.
3. Check SQL Server Instances
Azure SQL Databases and SQL Managed Instances may also have TLS configurations that need checking:
SELECT
location,
fully_qualified_domain_name,
minimal_tls_version,
state
FROM
azure.sql.vw_servers
WHERE
subscriptionId = '123e4567-e89b-12d3-a456-426614174000'
AND minimal_tls_version < '1.2';
This shows all SQL servers with a minimal TLS version set below 1.2.
We’d love to hear your feedback. ⭐ us on GitHub and let us know how StackQL helps you manage your Azure resources!