StackQL allows you to query and interact with your cloud and SaaS assets using a simple SQL framework
Understanding entitlements across a GCP org with a complex hierarchy is a challenge. I have taken and data-centric approach to this in this article.
Prerequisites include setting up a Jupyter environment with StackQL (done here using Docker): stackql-jupyter-demo. You will also need a service account and associated key with the roles/iam.securityReviewer role.
I've broken the notebook bits down to explain...
Setup
This step includes importing the required libraries (pandas etc.) and instantiating a StackQL client with the service account creds you created before. You will supply your root node here using the org_id and org_name variables.
Next we will create some helper functions; these will help us enumerate nodes in the GCP org resource hierarchy and fetch and unnest IAM policies.
Get all nodes in the resource hierarchy
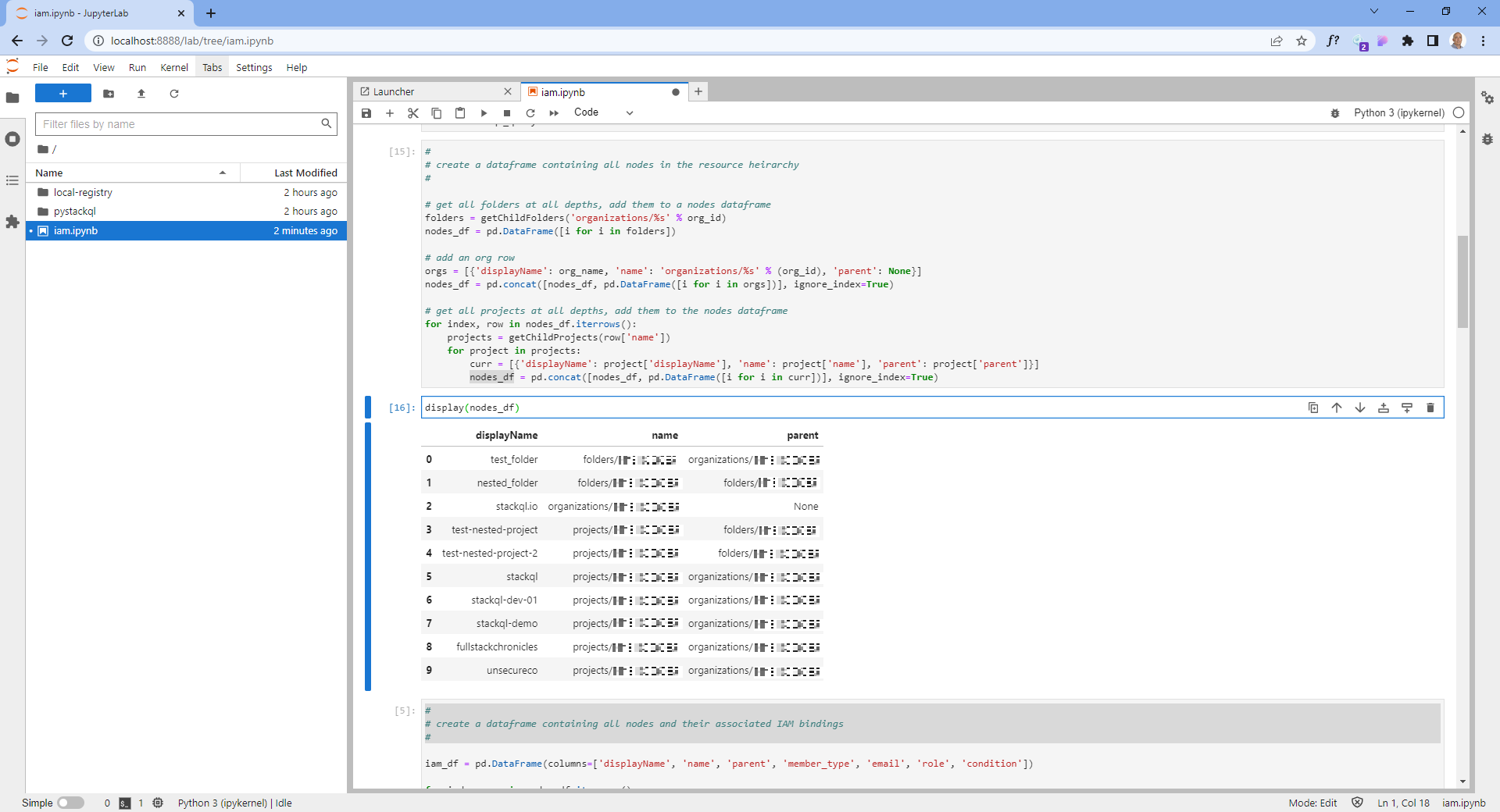
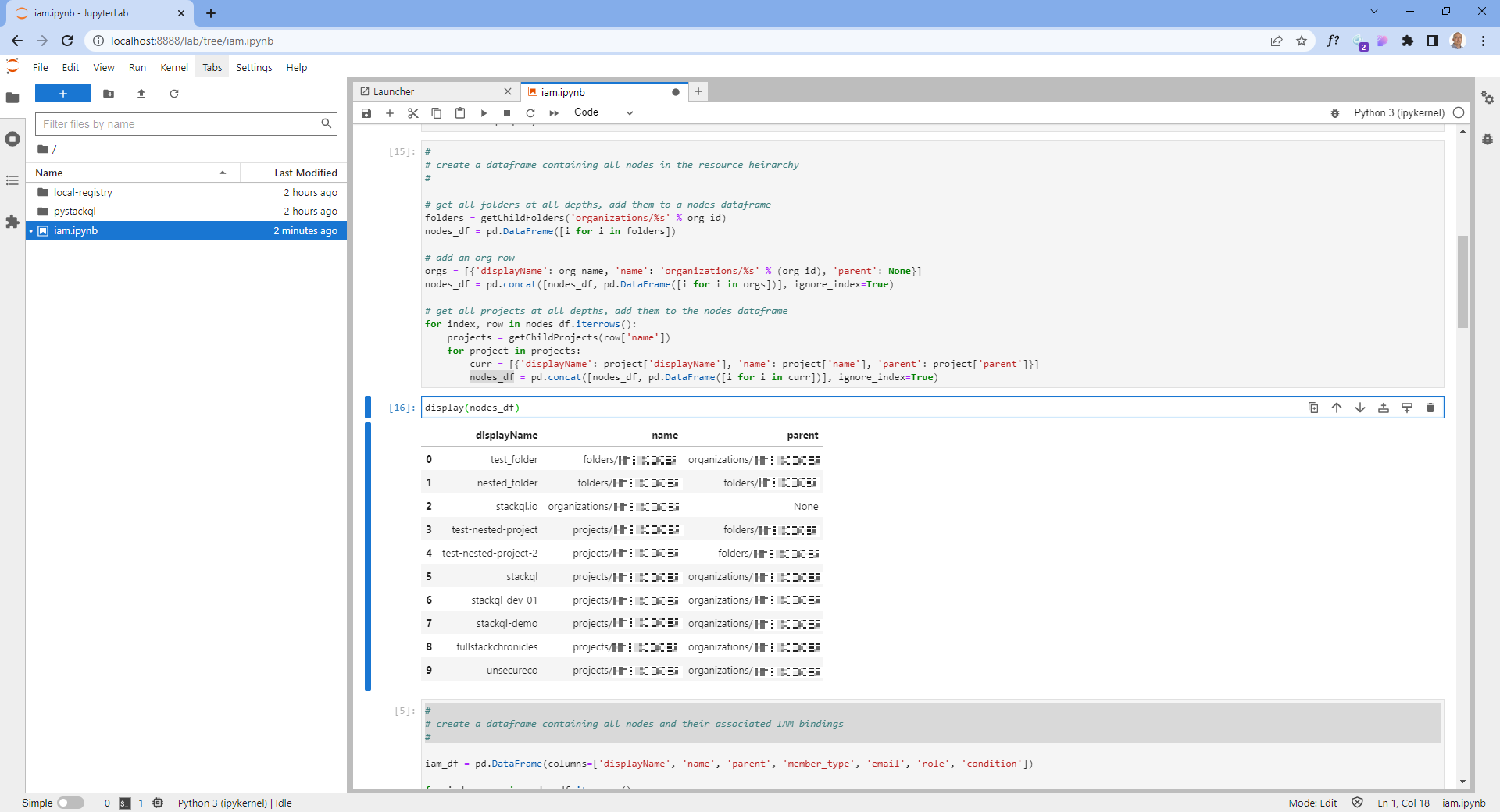
Create a dataframe containing all nodes in the resource hierarchy, including the root node (the organization), each folder with its subfolders, and projects. The functions used will search each folder in the hierarchy to find its subfolders and projects using a depth-first search approach.
Inspecting the output, it looks like this:
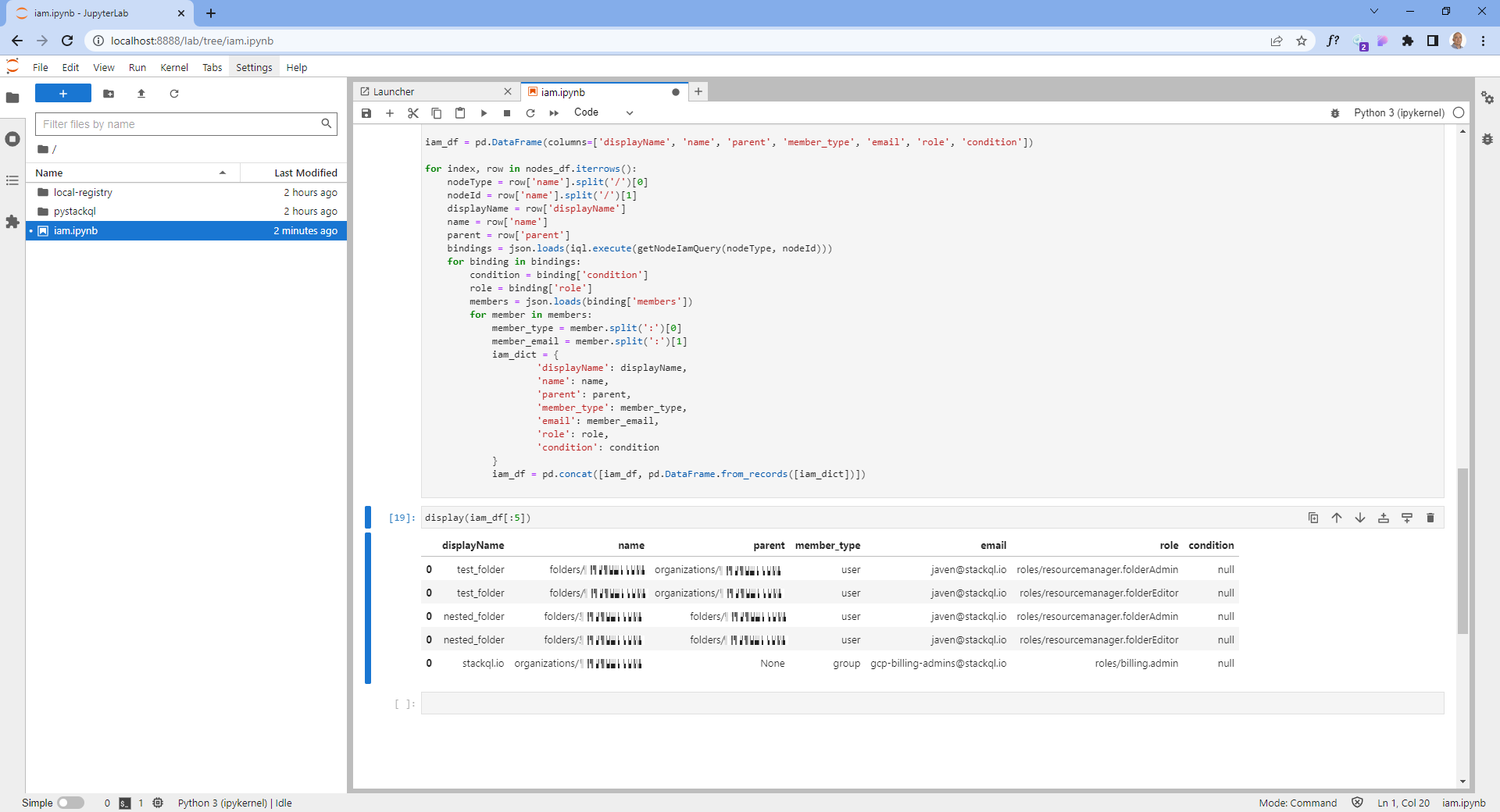
Create a dataset including each node and its associated IAM policies
This step will fetch all of the policies applied at each node in the data structure we created in the previous step.
The IAM policies response from SELECT role, members FROM google.cloudresourcemanager.project_iam_policies ... presents some challenges as members is a nested list which we need to unnest (or explode) along with the associated role and conditions (if they exist).
This bit of massaging will give us a SQL-friendly model we can use for analysis and join with another data source (such as a list of identities from an identity provider).
Inspecting the Final Output
We can now peek at the final data set, which looks like this:
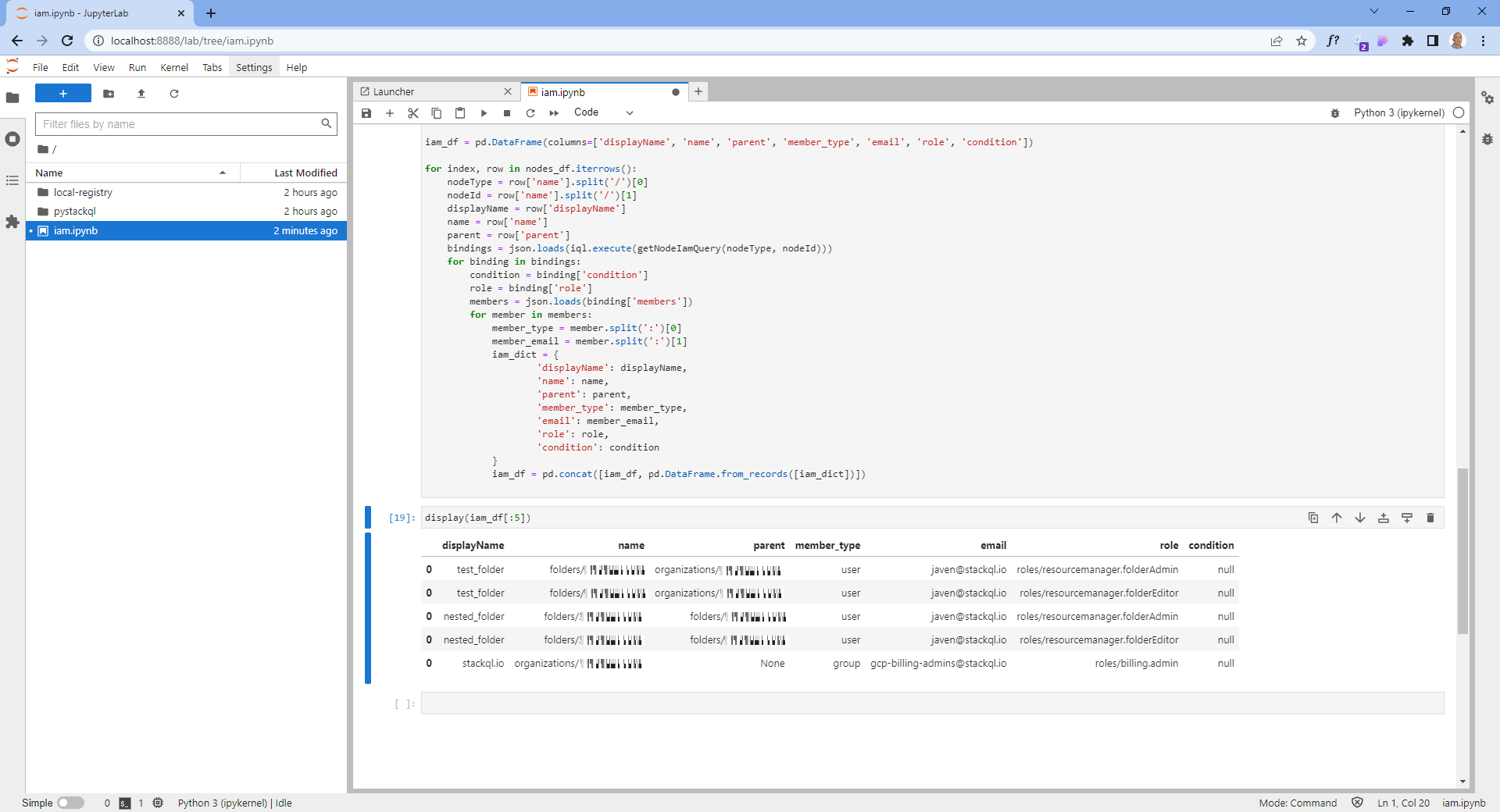
What's next? You could now join this with data from your IdP, or other SaaS services to correlate entitlements across your entire estate. You could also drill into specific service accounts, users, or groups. Queries are run in real-time, so you can refresh the data by simply rerunning the cells.
Welcome your feedback by getting in touch or raising issues at stackql/stackql or stackql/stackql-provider-registry, give us some ⭐️ love while you are there!
Enjoy!