AWS Global Inventory
In this guide, we will demonstrate using StackQL - a powerful dev tool that enables querying and deploying cloud infrastructure and resources using SQL syntax - to generate a comprehensive inventory of all resources, in all services, in all regions within a given AWS account.
Tested with embedded sql backend postgres sql backend macos linux powershell
How it works
StackQL implements a SQL engine which can process multiple queries asynchronously, for instance:
SELECT region, COUNT(*) as num_functions
FROM aws.lambda.functions
WHERE region IN (
'us-east-1','us-east-2','us-west-1','us-west-2',
'ap-south-1','ap-northeast-3','ap-northeast-2',
'ap-southeast-1','ap-southeast-2','ap-northeast-1',
'ca-central-1','eu-central-1','eu-west-1',
'eu-west-2','eu-west-3','eu-north-1','sa-east-1')
GROUP BY region;
The above query is actually 17 queries run in parallel (one query for each region), the results are aggregated and presented as a report. Using pystackql - a Python wrapper for StackQL - we can iterate through all resources in all services for all regions which are supported by the given service. The result is a report of how many instances are deployed of each resource in each region, as seen in the example below:
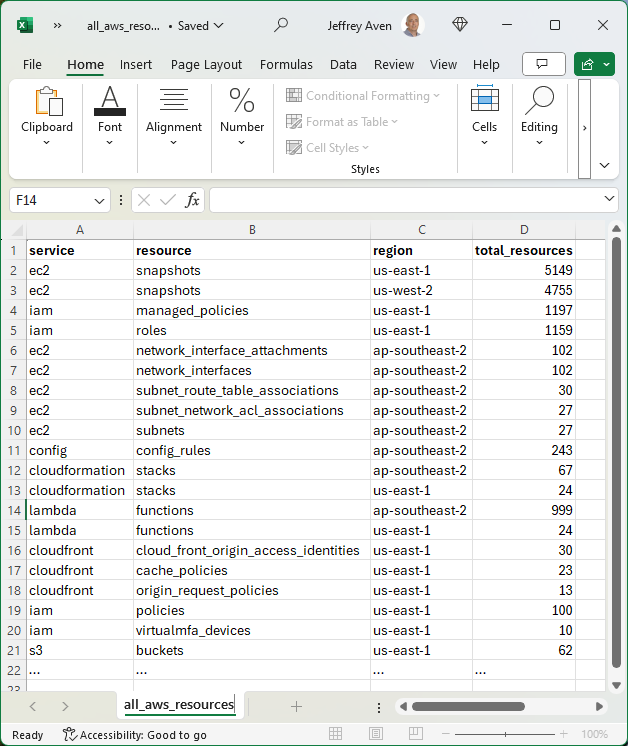
Prerequisites
pystackqlwhich can be installed usingpip install pystackql- An AWS user or a role (can be assumed using
sts assume-role) with theReadOnlyAccesspolicy or greater attached AWS_ACCESS_KEY_IDandAWS_SECRET_ACCESS_KEYenvironment variables set (this can be done automatically using AWS Cloud Shell)
The Code
The following code performs the following actions:
- Defines a list of all AWS regions (
regions) and a list of regions supported for each service (supported_regions), more info on derivingsupported_regionscan be found at AWS Service Support by Region at a Glance - Pulls the
awsandawsStackQL providers if they're not already installed. - Iterates through each service (using
SHOW SERVICES), then for each service iterates through each resource (usingSHOW RESOURCES) SELECT's all instances of each resource across all regions asynchronously, groups the data by region and counts the instance of each resource for each region
Here it is...
- stackql-aws-inventory.py
- resources.py
- regions.py
from regions import supported_regions, regions
from resources import excluded_resources, resource_filters
import time
from pystackql import StackQL
import pandas as pd
stackql = StackQL(output='pandas', page_limit=-1, execution_concurrency_limit=-1)
def pull_stackql_providers():
providers_df = stackql.execute("SHOW PROVIDERS")
is_aws_installed = 'aws' in providers_df['name'].values if not providers_df.empty else False
if not is_aws_installed:
print("aws not installed. Installing aws")
res = stackql.executeStmt("REGISTRY PULL aws")
print(res['message'])
def get_s3_buckets():
# special case for s3 buckets
int_results_df = pd.DataFrame(columns=['bucket', 'region'])
buckets = stackql.execute("""
SELECT bucket_name
FROM aws.s3.buckets WHERE region = 'us-east-1';
""")['bucket_name'].values.tolist()
for bucket in buckets:
regional_domain_query = f"""
SELECT
bucket_name,
bucket_location
FROM aws.s3.bucket WHERE region = 'us-east-1' AND data__Identifier = '{bucket}'
"""
print(f"Checking location for {bucket}...")
regional_domain_name_df = stackql.execute(regional_domain_query)
# Extract the region from the domain name
if not regional_domain_name_df.empty:
bucket_name = regional_domain_name_df['bucket_name'].values[0]
bucket_location = regional_domain_name_df['bucket_location'].values[0]
print("bucket_name: ", bucket_name)
print("bucket_location: ", bucket_location)
new_row = {'bucket': bucket_name, 'region': bucket_location}
int_results_df = pd.concat([int_results_df, pd.DataFrame([new_row])], ignore_index=True)
# Group by region and count the total resources (buckets) in each region
grouped = int_results_df.groupby('region').size().reset_index(name='total_resources')
grouped['svc'] = 's3'
grouped['res'] = 'buckets'
output_df = grouped[['svc', 'res', 'region', 'total_resources']]
return output_df
def main():
start_time = time.time()
pull_stackql_providers()
results_df = pd.DataFrame(columns=['svc', 'res', 'region', 'total_resources'])
# get all enumerable aws services
services_df = stackql.execute("SHOW SERVICES IN aws")
for svcIx, svcRow in services_df.iterrows():
service = svcRow['name']
if service in supported_regions:
# check all enumerable aws resources in the service against supported regions
resources_df = stackql.execute(f"SHOW RESOURCES IN aws.{service}")
plural_resources = [resource for resource in resources_df['name'].tolist() if resource.endswith('s')]
if plural_resources:
for resource in plural_resources:
print(f"Checking {resource} in {service}...")
if service == 's3' and resource == 'buckets':
print(f"Checking location for s3 buckets...")
resource_df = get_s3_buckets()
else:
# should we skip this service?
if service in excluded_resources and resource in excluded_resources[service]:
continue
# check if the resource is global or regional
if 'global' in supported_regions[service]:
regions_in = ", ".join([f"'{region}'" for region in regions])
else:
regions_in = ", ".join([f"'{region}'" for region in supported_regions[service]])
# check if there are additional where clauses for this resource
where_clause = resource_filters.get(service, {}).get(resource, '')
resource_df = stackql.execute(f"""
SELECT '{service}' as svc, '{resource}' as res, region, COUNT(*) as total_resources
FROM aws.{service}.{resource}
WHERE region IN ({regions_in}){where_clause}
GROUP BY svc, res, region
""")
if not resource_df.empty:
# Append resource_df to the results_df
if not 'error' in resource_df.columns:
results_df = pd.concat([results_df, resource_df], ignore_index=True)
end_time = time.time()
elapsed_time = end_time - start_time
print(f"Elapsed time: {elapsed_time:.2f} seconds")
results_df.to_csv('all_aws_resources.csv', index=False)
if __name__ == "__main__":
main()
# exclude these resources
excluded_resources = {
'cloudformation': ['public_type_versions'],
'gamelift': ['locations'],
'codepipeline': ['custom_action_types'],
'ssm': ['patch_baselines'],
'iot': ['domain_configurations'],
'ce': ['anomaly_monitors', 'anomaly_subscriptions'],
}
# apply an additional filter to these resources, to filter defaults or AWS managed resources
resource_filters = {
"appconfig": {
"extensions": " AND SPLIT_PART(id, '.', 1) <> 'AWS'",
},
"apprunner": {
"observability_configurations": " AND SPLIT_PART(observability_configuration_arn, '/', 2) <> 'DefaultConfiguration'",
"auto_scaling_configurations": " AND SPLIT_PART(auto_scaling_configuration_arn, '/', 2) <> 'DefaultConfiguration'",
},
"athena": {
"work_groups": " AND name <> 'primary'",
"data_catalogs": " AND name <> 'AwsDataCatalog'",
},
"cassandra": {
"keyspaces": " AND keyspace_name <> 'system_multiregion_info'",
},
"codedeploy": {
"deployment_configs": " AND SPLIT_PART(deployment_config_name, '.', 1) <> 'CodeDeployDefault'",
},
"ec2": {
"snapshots": " AND ownerAlias <> 'amazon'",
},
"elasticache": {
"users": " AND user_id <> 'default'",
},
"events": {
"event_buses": " AND name <> 'default'",
},
"iam": {
"managed_policies": " AND SPLIT_PART(policy_arn, '/', 1) <> 'arn:aws:iam::aws:policy'",
"policies": " AND SPLIT_PART(Arn, '/', 1) <> 'arn:aws:iam::aws:policy'",
},
"kms": {
"aliases": " AND SPLIT_PART(alias_name, '/', 2) <> 'aws'",
},
"memorydb": {
"acls": " AND acl_name <> 'open-access'",
"users": " AND user_name <> 'default'",
"parameter_groups": " AND SPLIT_PART(parameter_group_name, '.', 1) <> 'default'",
},
"ram": {
"permissions": " AND SPLIT_PART(arn, '/', 1) <> 'arn:aws:ram::aws:permission'",
},
"route53resolver" : {
"resolver_rule_associations": " AND SPLIT_PART(resolver_rule_association_id, '-', 2) <> 'autodefined'",
"resolver_rules": " AND SPLIT_PART(resolver_rule_id, '-', 2) <> 'autodefined'",
},
"scheduler": {
"schedule_groups": " AND name <> 'default'",
},
"ssm": {
"documents": " AND SUBSTRING(name, 1, 3) <> 'AWS' AND SUBSTRING(name, 1, 6) <> 'Amazon' AND SUBSTRING(name, 1, 3) <> 'Aws' AND name NOT IN ('AlertLogic-MDR', 'CrowdStrike-FalconSensorDeploy', 'DynatraceOneAgent', 'FalconSensor-Linux', 'FalconSensor-Windows', 'New-Relic-infrastructure-monitoring-agent', 'TrendMicro-CloudOne-WorkloadSecurity')",
},
}
# all AWS regions
regions = ['us-east-1', 'us-east-2', 'us-west-1', 'us-west-2', 'ap-south-1', 'ap-northeast-3', 'ap-northeast-2', 'ap-southeast-1', 'ap-southeast-2', 'ap-northeast-1', 'ca-central-1', 'eu-central-1', 'eu-west-1', 'eu-west-2', 'eu-west-3', 'eu-north-1', 'sa-east-1']
# regions supported by services
supported_regions = {
'accessanalyzer': ['global'],
'acmpca': ['global'],
'amplify': ['us-east-1', 'us-east-2', 'us-west-1', 'us-west-2', 'ap-south-1',
'ap-northeast-2', 'ap-southeast-1', 'ap-southeast-2',
'ap-northeast-1', 'ca-central-1', 'eu-central-1', 'eu-west-1',
'eu-west-2', 'eu-west-3', 'eu-north-1', 'sa-east-1'],
'apigateway': ['us-east-1', 'us-east-2', 'us-west-1', 'us-west-2',
'ap-south-1', 'ap-northeast-2', 'ap-southeast-1',
'ap-southeast-2', 'ap-northeast-1', 'ca-central-1',
'eu-central-1', 'eu-west-1', 'eu-west-2', 'eu-west-3',
'eu-north-1', 'sa-east-1'],
'apigatewayv2': ['global'],
'appconfig': ['global'],
'appflow': ['us-east-1', 'us-east-2', 'us-west-1', 'us-west-2', 'ap-south-1',
'ap-northeast-2', 'ap-southeast-1', 'ap-southeast-2',
'ap-northeast-1', 'ca-central-1', 'eu-central-1', 'eu-west-1',
'eu-west-2', 'eu-west-3', 'sa-east-1'],
'applicationinsights': ['global'],
'apprunner': ['us-east-1', 'us-east-2', 'us-west-2', 'ap-south-1',
'ap-southeast-1', 'ap-southeast-2', 'ap-northeast-1',
'eu-central-1', 'eu-west-1', 'eu-west-2', 'eu-west-3'],
'appstream': ['us-east-1', 'us-east-2', 'us-west-2', 'ap-south-1',
'ap-northeast-2', 'ap-southeast-1', 'ap-southeast-2',
'ap-northeast-1', 'ca-central-1', 'eu-central-1', 'eu-west-1',
'eu-west-2', 'sa-east-1'],
'appsync': ['global'],
'aps': ['us-east-1', 'us-east-2', 'us-west-2', 'ap-south-1', 'ap-northeast-2',
'ap-southeast-1', 'ap-southeast-2', 'ap-northeast-1', 'eu-central-1',
'eu-west-1', 'eu-west-2', 'eu-west-3', 'eu-north-1', 'sa-east-1'],
'arczonalshift': ['global'],
'athena': ['us-east-1', 'us-east-2', 'us-west-2', 'ap-southeast-1',
'ap-southeast-2', 'ap-northeast-1', 'eu-west-1', 'eu-north-1'],
'autoscaling': ['global'],
'backup': ['global'],
'backupgateway': ['global'],
'batch': ['global'],
'budgets': ['us-east-1', 'us-east-2', 'us-west-1', 'us-west-2', 'ap-south-1',
'ap-northeast-2', 'ap-southeast-1', 'ap-southeast-2',
'ap-northeast-1', 'ca-central-1', 'eu-central-1', 'eu-west-1',
'eu-west-2', 'eu-west-3', 'sa-east-1'],
'cassandra': ['us-east-1', 'us-east-2', 'us-west-1', 'us-west-2', 'ap-south-1',
'ap-northeast-2', 'ap-southeast-1', 'ap-southeast-2',
'ap-northeast-1', 'ca-central-1', 'eu-central-1', 'eu-west-1',
'eu-west-2', 'eu-west-3', 'eu-north-1', 'sa-east-1'],
'ce': ['global'],
'chatbot': ['global'],
'cleanrooms': ['us-east-1', 'us-east-2', 'us-west-2', 'ap-northeast-2',
'ap-southeast-1', 'ap-southeast-2', 'ap-northeast-1',
'eu-central-1', 'eu-west-1', 'eu-west-2', 'eu-north-1'],
'cloudformation': ['global'],
'cloudfront': ['us-east-1'],
'cloudtrail': ['global'],
'cloudwatch': ['global'],
'codeartifact': ['us-east-1', 'us-east-2', 'us-west-2', 'ap-south-1',
'ap-southeast-1', 'ap-southeast-2', 'ap-northeast-1',
'eu-central-1', 'eu-west-1', 'eu-west-2', 'eu-west-3',
'eu-north-1'],
'codebuild': ['us-east-1', 'us-east-2', 'us-west-2', 'ap-south-1',
'ap-southeast-1', 'ap-southeast-2', 'ap-northeast-1',
'eu-central-1', 'eu-west-1', 'sa-east-1'],
'codedeploy': ['global'],
'codeguruprofiler': ['us-east-1', 'us-east-2', 'us-west-2', 'ap-southeast-1',
'ap-southeast-2', 'ap-northeast-1', 'eu-central-1',
'eu-west-1', 'eu-west-2', 'eu-north-1'],
'codegurureviewer': ['us-east-1', 'us-east-2', 'us-west-2', 'ap-southeast-1',
'ap-southeast-2', 'ap-northeast-1', 'eu-central-1',
'eu-west-1', 'eu-west-2', 'eu-north-1'],
'codepipeline': ['us-east-1', 'us-east-2', 'us-west-1', 'us-west-2',
'ap-south-1', 'ap-northeast-2', 'ap-southeast-1',
'ap-southeast-2', 'ap-northeast-1', 'ca-central-1',
'eu-central-1', 'eu-west-1', 'eu-west-2', 'eu-west-3',
'eu-north-1', 'sa-east-1'],
'codestarconnections': ['us-east-1', 'us-east-2', 'us-west-1', 'us-west-2',
'ap-south-1', 'ap-northeast-2', 'ap-southeast-1',
'ap-southeast-2', 'ap-northeast-1', 'ca-central-1',
'eu-central-1', 'eu-west-1', 'eu-west-2', 'eu-west-3',
'eu-north-1', 'sa-east-1'],
'codestarnotifications': ['us-east-1', 'us-east-2', 'us-west-1', 'us-west-2',
'ap-south-1', 'ap-northeast-2', 'ap-southeast-1',
'ap-southeast-2', 'ap-northeast-1', 'ca-central-1',
'eu-central-1', 'eu-west-1', 'eu-west-2',
'eu-west-3', 'eu-north-1', 'sa-east-1'],
'cognito': ['global'],
'comprehend': ['us-east-1', 'us-east-2', 'us-west-2', 'ap-south-1',
'ap-northeast-2', 'ap-southeast-1', 'ap-southeast-2',
'ap-northeast-1', 'ca-central-1', 'eu-central-1', 'eu-west-1',
'eu-west-2'],
'config': ['global'],
'connect': ['us-east-1', 'us-west-2', 'ap-northeast-2', 'ap-southeast-1',
'ap-southeast-2', 'ap-northeast-1', 'ca-central-1', 'eu-central-1',
'eu-west-2'],
'databrew': ['us-east-1', 'us-east-2', 'us-west-1', 'us-west-2', 'ap-south-1',
'ap-northeast-2', 'ap-southeast-1', 'ap-southeast-2',
'ap-northeast-1', 'ca-central-1', 'eu-central-1', 'eu-west-1',
'eu-west-2', 'eu-west-3', 'eu-north-1', 'sa-east-1'],
'datapipeline': ['us-east-1', 'us-west-2', 'ap-southeast-2', 'ap-northeast-1',
'eu-west-1'],
'datasync': ['global'],
'detective': ['us-east-1', 'us-east-2', 'us-west-1', 'us-west-2', 'ap-south-1',
'ap-northeast-2', 'ap-southeast-1', 'ap-southeast-2',
'ap-northeast-1', 'ca-central-1', 'eu-central-1', 'eu-west-1',
'eu-west-2', 'eu-west-3', 'eu-north-1', 'sa-east-1'],
'devopsguru': ['us-east-1', 'us-east-2', 'us-west-1', 'us-west-2',
'ap-south-1', 'ap-northeast-2', 'ap-southeast-1',
'ap-southeast-2', 'ap-northeast-1', 'ca-central-1',
'eu-central-1', 'eu-west-1', 'eu-west-2', 'eu-west-3',
'eu-north-1', 'sa-east-1'],
'directoryservice': ['us-east-1', 'us-west-2', 'ap-southeast-1',
'ap-southeast-2', 'ap-northeast-1', 'eu-west-1'],
'dms': ['us-east-1', 'us-east-2', 'us-west-2', 'ap-southeast-1',
'ap-southeast-2', 'ap-northeast-1', 'eu-central-1', 'eu-west-1',
'eu-north-1'],
'dynamodb': ['global'],
'ec2': ['global'],
'ecr': ['us-east-1'],
'ecs': ['global'],
'efs': ['global'],
'eks': ['global'],
'elasticache': ['global'],
'elasticbeanstalk': ['global'],
'elasticloadbalancingv2': ['global'],
'emr': ['global'],
'emrcontainers': ['us-east-1', 'us-east-2', 'us-west-1', 'us-west-2',
'ap-south-1', 'ap-northeast-2', 'ap-southeast-1',
'ap-southeast-2', 'ap-northeast-1', 'ca-central-1',
'eu-central-1', 'eu-west-1', 'eu-west-2'],
'emrserverless': ['global'],
'events': ['global'],
'eventschemas': ['global'],
'fis': ['us-east-1', 'us-east-2', 'us-west-1', 'us-west-2', 'ap-south-1',
'ap-northeast-2', 'ap-southeast-1', 'ap-southeast-2', 'ap-northeast-1',
'ca-central-1', 'eu-central-1', 'eu-west-1', 'eu-west-2', 'eu-west-3',
'eu-north-1', 'sa-east-1'],
'forecast': ['us-east-1', 'us-east-2', 'us-west-2', 'ap-south-1',
'ap-northeast-2', 'ap-southeast-1', 'ap-southeast-2',
'ap-northeast-1', 'eu-central-1', 'eu-west-1'],
'frauddetector': ['us-east-1', 'us-east-2', 'us-west-2', 'ap-southeast-1',
'ap-southeast-2', 'eu-west-1'],
'fsx': ['global'],
'gamelift': ['us-east-1', 'us-east-2', 'us-west-1', 'us-west-2', 'ap-south-1',
'ap-northeast-2', 'ap-southeast-1', 'ap-southeast-2',
'ap-northeast-1', 'ca-central-1', 'eu-central-1', 'eu-west-1',
'eu-west-2', 'sa-east-1'],
'globalaccelerator': ['us-east-1'],
'grafana': ['us-east-1', 'us-east-2', 'us-west-2', 'ap-northeast-2',
'ap-southeast-1', 'ap-southeast-2', 'ap-northeast-1',
'eu-central-1', 'eu-west-1', 'eu-west-2'],
'greengrassv2': ['us-east-1', 'us-east-2', 'us-west-2', 'ap-south-1',
'ap-northeast-2', 'ap-southeast-1', 'ap-southeast-2',
'ap-northeast-1', 'ca-central-1', 'eu-central-1', 'eu-west-1',
'eu-west-2'],
'groundstation': ['us-east-1', 'us-east-2', 'us-west-2', 'ap-northeast-2',
'ap-southeast-1', 'ap-southeast-2', 'eu-central-1',
'eu-west-1', 'eu-north-1', 'sa-east-1'],
'guardduty': ['global'],
'healthlake': ['us-east-1', 'us-east-2', 'us-west-2', 'ap-south-1'],
'iam': ['us-east-1'],
'imagebuilder': ['global'],
'inspector': ['us-east-1', 'us-east-2', 'us-west-1', 'us-west-2', 'ap-south-1',
'ap-northeast-2', 'ap-southeast-2', 'ap-northeast-1',
'eu-central-1', 'eu-west-1', 'eu-west-2', 'eu-north-1'],
'inspectorv2': ['global'],
'internetmonitor': ['global'],
'iot': ['us-east-1', 'us-east-2', 'us-west-1', 'us-west-2', 'ap-south-1',
'ap-northeast-2', 'ap-southeast-1', 'ap-southeast-2', 'ap-northeast-1',
'ca-central-1', 'eu-central-1', 'eu-west-1', 'eu-west-2', 'eu-west-3',
'eu-north-1'],
'iotanalytics': ['us-east-1', 'us-east-2', 'us-west-2', 'ap-south-1',
'ap-southeast-2', 'ap-northeast-1', 'eu-central-1',
'eu-west-1'],
'iotevents': ['us-east-1', 'us-east-2', 'us-west-2', 'ap-south-1',
'ap-northeast-2', 'ap-southeast-1', 'ap-southeast-2',
'ap-northeast-1', 'ca-central-1', 'eu-central-1', 'eu-west-1',
'eu-west-2'],
'iotfleethub': ['us-east-1', 'us-east-2', 'us-west-2', 'ap-south-1',
'ap-northeast-2', 'ap-southeast-1', 'ap-southeast-2',
'ap-northeast-1', 'ca-central-1', 'eu-central-1', 'eu-west-1',
'eu-west-2', 'eu-north-1'],
'iotfleetwise': ['us-east-1', 'eu-central-1'],
'iotsitewise': ['us-east-1', 'us-east-2', 'us-west-2', 'ap-south-1',
'ap-northeast-2', 'ap-southeast-1', 'ap-southeast-2',
'ap-northeast-1', 'ca-central-1', 'eu-central-1',
'eu-west-1'],
'iotwireless': ['us-east-1', 'us-west-2', 'ap-southeast-2', 'ap-northeast-1',
'eu-central-1', 'eu-west-1', 'sa-east-1'],
'ivs': ['us-east-1', 'us-west-2', 'ap-south-1', 'ap-northeast-2',
'ap-northeast-1', 'eu-central-1', 'eu-west-1'],
'ivschat': ['us-east-1', 'us-west-2', 'ap-south-1', 'ap-northeast-2',
'ap-northeast-1', 'eu-central-1', 'eu-west-1'],
'kafkaconnect': ['us-east-1', 'us-east-2', 'us-west-1', 'us-west-2',
'ap-south-1', 'ap-northeast-2', 'ap-southeast-1',
'ap-southeast-2', 'ap-northeast-1', 'ca-central-1',
'eu-central-1', 'eu-west-1', 'eu-west-2', 'eu-west-3',
'eu-north-1', 'sa-east-1'],
'kendra': ['us-east-1', 'us-east-2', 'us-west-2', 'ap-south-1',
'ap-southeast-1', 'ap-southeast-2', 'ap-northeast-1',
'ca-central-1', 'eu-west-1', 'eu-west-2'],
'kinesis': ['global'],
'kinesisanalyticsv2': ['global'],
'kinesisfirehose': ['global'],
'kms': ['global'],
'lakeformation': ['global'],
'lambda': ['us-east-1', 'us-east-2', 'us-west-1', 'us-west-2', 'ap-south-1',
'ap-northeast-2', 'ap-southeast-1', 'ap-southeast-2',
'ap-northeast-1', 'ca-central-1', 'eu-central-1', 'eu-west-1',
'eu-west-2', 'eu-west-3', 'eu-north-1', 'sa-east-1'],
'lex': ['us-east-1', 'us-west-2', 'ap-northeast-2', 'ap-southeast-1',
'ap-southeast-2', 'ap-northeast-1', 'ca-central-1', 'eu-central-1',
'eu-west-1', 'eu-west-2'],
'lightsail': ['us-east-1', 'us-east-2', 'us-west-2', 'ap-south-1',
'ap-northeast-2', 'ap-southeast-1', 'ap-southeast-2',
'ap-northeast-1', 'ca-central-1', 'eu-central-1', 'eu-west-1',
'eu-west-2', 'eu-west-3', 'eu-north-1'],
'logs': ['global'],
'lookoutequipment': ['us-east-1', 'ap-northeast-2', 'eu-west-1'],
'lookoutmetrics': ['us-east-1', 'us-east-2', 'us-west-2', 'ap-southeast-1',
'ap-southeast-2', 'ap-northeast-1', 'eu-central-1',
'eu-west-1', 'eu-north-1'],
'lookoutvision': ['us-east-1', 'us-east-2', 'us-west-2', 'ap-northeast-2',
'ap-northeast-1', 'eu-central-1', 'eu-west-1'],
'm2': ['global'],
'macie': ['global'],
'mediaconnect': ['global'],
'medialive': ['us-east-1', 'us-east-2', 'us-west-2', 'ap-south-1',
'ap-northeast-3', 'ap-northeast-2', 'ap-southeast-1',
'ap-southeast-2', 'ap-northeast-1', 'ca-central-1',
'eu-central-1', 'eu-west-1', 'eu-west-2', 'eu-west-3',
'eu-north-1', 'sa-east-1'],
'mediapackage': ['us-east-1', 'us-east-2', 'us-west-1', 'us-west-2',
'ap-south-1', 'ap-northeast-2', 'ap-southeast-1',
'ap-southeast-2', 'ap-northeast-1', 'eu-central-1',
'eu-west-1', 'eu-west-2', 'eu-west-3', 'eu-north-1',
'sa-east-1'],
'mediapackagev2': ['global'],
'memorydb': ['us-east-1', 'us-east-2', 'us-west-1', 'us-west-2', 'ap-south-1',
'ap-northeast-2', 'ap-southeast-1', 'ap-southeast-2',
'ap-northeast-1', 'ca-central-1', 'eu-central-1', 'eu-west-1',
'eu-west-2', 'eu-north-1', 'sa-east-1'],
'msk': ['global'],
'mwaa': ['us-east-1', 'us-east-2', 'us-west-2', 'ap-south-1', 'ap-northeast-2',
'ap-southeast-1', 'ap-southeast-2', 'ap-northeast-1', 'ca-central-1',
'eu-central-1', 'eu-west-1', 'eu-west-2', 'eu-west-3', 'eu-north-1',
'sa-east-1'],
'neptune': ['global'],
'networkfirewall': ['global'],
'networkmanager': ['global'],
'nimblestudio': ['us-east-1', 'us-east-2', 'us-west-2', 'ap-southeast-1',
'ap-southeast-2', 'ap-northeast-1', 'ca-central-1',
'eu-central-1', 'eu-west-1', 'eu-west-2', 'eu-north-1'],
'oam': ['global'],
'omics': ['us-east-1', 'us-west-2', 'ap-southeast-1', 'eu-central-1',
'eu-west-1', 'eu-west-2'],
'opensearchserverless': ['us-east-1', 'us-east-2', 'us-west-2',
'ap-southeast-1', 'ap-southeast-2', 'ap-northeast-1',
'eu-central-1', 'eu-west-1'],
'opsworkscm': ['us-east-1', 'us-east-2', 'us-west-1', 'us-west-2',
'ap-southeast-1', 'ap-southeast-2', 'ap-northeast-1',
'eu-central-1', 'eu-west-1'],
'organizations': ['us-east-1', 'us-east-2', 'us-west-1', 'us-west-2',
'ap-south-1', 'ap-northeast-3', 'ap-northeast-2',
'ap-southeast-1', 'ap-southeast-2', 'ap-northeast-1',
'ca-central-1', 'eu-central-1', 'eu-west-1', 'eu-west-2',
'eu-west-3', 'eu-north-1', 'sa-east-1'],
'osis': ['us-east-1', 'us-east-2', 'us-west-1', 'us-west-2', 'ap-south-1',
'ap-northeast-2', 'ap-southeast-1', 'ap-southeast-2',
'ap-northeast-1', 'ca-central-1', 'eu-central-1', 'eu-west-1',
'eu-west-2', 'eu-north-1', 'sa-east-1'],
'pcaconnectorad': ['global'],
'personalize': ['us-east-1', 'us-east-2', 'us-west-2', 'ap-south-1',
'ap-northeast-2', 'ap-southeast-1', 'ap-southeast-2',
'ap-northeast-1', 'ca-central-1', 'eu-central-1',
'eu-west-1'],
'pinpoint': ['us-east-1', 'us-east-2', 'us-west-2', 'ap-south-1',
'ap-northeast-2', 'ap-southeast-1', 'ap-southeast-2',
'ap-northeast-1', 'ca-central-1', 'eu-central-1', 'eu-west-1',
'eu-west-2'],
'pipes': ['global'],
'proton': ['us-east-1', 'us-east-2', 'us-west-2', 'ap-northeast-2',
'ap-southeast-1', 'ap-southeast-2', 'ap-northeast-1',
'ca-central-1', 'eu-central-1', 'eu-west-1', 'eu-west-2'],
'ram': ['global'],
'rds': ['us-east-1', 'us-east-2', 'us-west-2', 'ap-south-1', 'ap-northeast-2',
'ap-southeast-1', 'ap-southeast-2', 'ap-northeast-1', 'ca-central-1',
'eu-central-1', 'eu-west-1', 'eu-west-2', 'eu-north-1', 'sa-east-1'],
'redshift': ['global'],
'refactorspaces': ['global'],
'rekognition': ['us-east-1', 'us-east-2', 'us-west-1', 'us-west-2',
'ap-south-1', 'ap-northeast-2', 'ap-southeast-1',
'ap-southeast-2', 'ap-northeast-1', 'ca-central-1',
'eu-central-1', 'eu-west-1', 'eu-west-2'],
'resiliencehub': ['us-east-1', 'us-east-2', 'us-west-1', 'us-west-2',
'ap-south-1', 'ap-northeast-2', 'ap-southeast-1',
'ap-southeast-2', 'ap-northeast-1', 'ca-central-1',
'eu-central-1', 'eu-west-1', 'eu-west-2', 'eu-west-3',
'eu-north-1', 'sa-east-1'],
'resourceexplorer2': ['global'],
'resourcegroups': ['global'],
'robomaker': ['us-east-1', 'us-east-2', 'us-west-2', 'ap-southeast-1',
'ap-northeast-1', 'eu-central-1', 'eu-west-1'],
'route53': ['us-east-1'],
'route53recoverycontrol': ['us-east-1', 'us-west-2'],
'route53recoveryreadiness': ['us-east-1', 'us-west-2'],
'route53resolver': ['global'],
'rum': ['us-east-1', 'us-east-2', 'us-west-2', 'ap-southeast-1',
'ap-southeast-2', 'ap-northeast-1', 'eu-central-1', 'eu-west-1',
'eu-west-2', 'eu-north-1'],
's3': ['global'],
's3objectlambda': ['global'],
'sagemaker': ['global'],
'scheduler': ['global'],
'secretsmanager': ['global'],
'securityhub': ['ap-southeast-2'],
'servicecatalog': ['global'],
'servicecatalogappregistry': ['global'],
'ses': ['global'],
'signer': ['us-east-1', 'us-east-2', 'us-west-1', 'us-west-2', 'ap-south-1',
'ap-northeast-2', 'ap-southeast-1', 'ap-southeast-2',
'ap-northeast-1', 'ca-central-1', 'eu-central-1', 'eu-west-1',
'eu-west-2', 'eu-west-3', 'eu-north-1', 'sa-east-1'],
'sns': ['global'],
'sqs': ['global'],
'ssm': ['global'],
'ssmcontacts': ['us-east-1', 'us-east-2', 'us-west-1', 'us-west-2',
'ap-south-1', 'ap-northeast-2', 'ap-southeast-1',
'ap-southeast-2', 'ap-northeast-1', 'ca-central-1',
'eu-central-1', 'eu-west-1', 'eu-west-2', 'eu-west-3',
'eu-north-1', 'sa-east-1'],
'ssmincidents': ['us-east-1', 'us-east-2', 'us-west-1', 'us-west-2',
'ap-south-1', 'ap-northeast-2', 'ap-southeast-1',
'ap-southeast-2', 'ap-northeast-1', 'ca-central-1',
'eu-central-1', 'eu-west-1', 'eu-west-2', 'eu-west-3',
'eu-north-1', 'sa-east-1'],
'stepfunctions': ['global'],
'synthetics': ['global'],
'timestream': ['us-east-1', 'us-east-2', 'us-west-2', 'ap-southeast-2',
'ap-northeast-1', 'eu-central-1', 'eu-west-1'],
'transfer': ['global'],
'verifiedpermissions': ['global'],
'vpclattice': ['us-east-1', 'us-east-2', 'us-west-2', 'ap-southeast-1',
'ap-southeast-2', 'ap-northeast-1', 'ca-central-1',
'eu-central-1', 'eu-west-1', 'eu-west-2', 'eu-north-1'],
'wafv2': ['us-east-1'],
'workspacesweb': ['us-east-1', 'us-west-2', 'ap-south-1', 'ap-southeast-1',
'ap-northeast-1', 'ca-central-1', 'eu-central-1',
'eu-west-1', 'eu-west-2']
}